.png)
GPU关键指标(二)显存
NVIDIA GPU 显存有两种类型,GDDR 和 HBM,每种也有不同的型号。针对显存我们通常会关注两个指标:显存大小和显存带宽。
传统的 CV、NLP 模型往往比较小,而且基本都是 Compute bound 的,所以普遍对显存大小、带宽关注比较少;
而现在 LLM 模型很大,推理通常也是 IO bound,更大的GPU 显存和带宽可以提高 batch size值,提升LLM的训推效率;
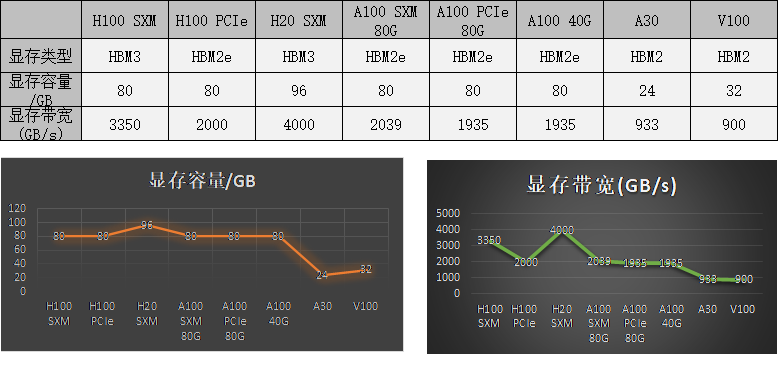
1)常见训练GPU显存:
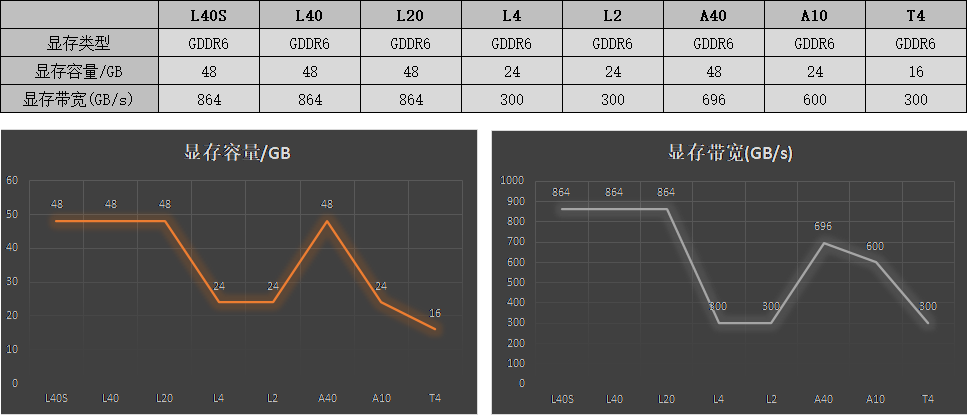
2)常见推理GPU显存:
3)显存对训练效率的影响
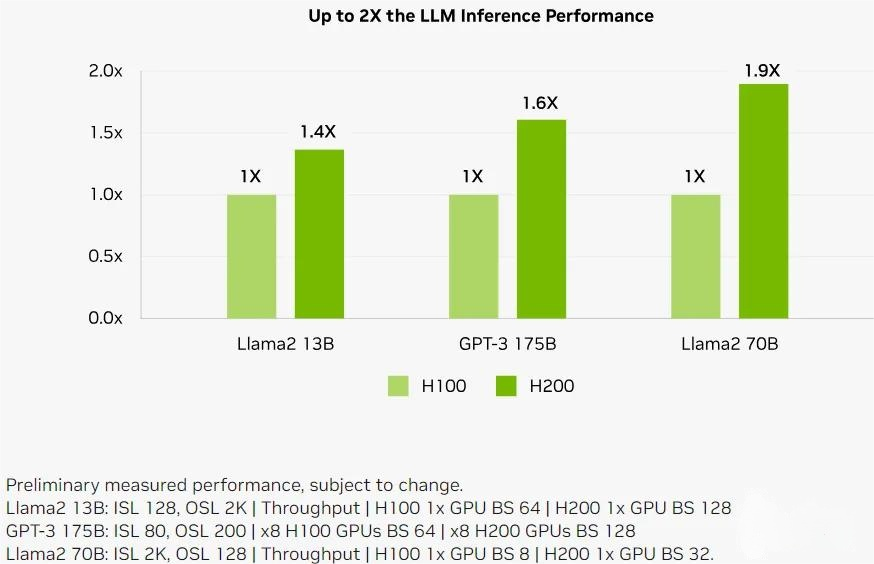
最近 NVIDIA 正式推出 H200 GPU,相比 H100,其主要的变化就是 GPU 显存从 80GB 升级到 141GB,显存带宽从 3.5TB/s 增加到 4.8TB/s
也就是说算力和 NVLink 没有任何提升,这可能是为了进一步适配大模型推理的需求:
如下所示为 H200 在同样数量情况下相比 H100 的 LLM 推理性能对比: